
Your "Private" LLM isn’t actually Self-Hosted
Moving beyond the "Self-Hosted" Myth

One of the most frequent misconceptions in organizations is the belief that using enterprise offerings such as OpenAI Enterprise, Anthropic via Amazon Bedrock, or Azure OpenAI means the model is “self-hosted” or running inside the company’s own infrastructure. Many executives hear the word "Enterprise" and mentally equate it with "On-Prem," which leads to significant misunderstandings regarding data boundaries and long-term costs.
This is not technically accurate.
In this article, I explain the different methodologies of using LLMs and clarify what actually happens in each case.
What an LLM Actually Does
At its core, an LLM is a mathematical function:
Output = Model(Input, Parameters)
where
Input = your prompt (case narrative, protocol, safety report, etc.)
Parameters = pretrained neural network weights
Output = generated text
The model does not automatically access your databases, your safety system, or your documents. It only processes the information you explicitly provide in the request.
The primary architectural decision is not the model itself but how you connect your enterprise data to the model.
There are three major architectural LLM methodologies in use today.
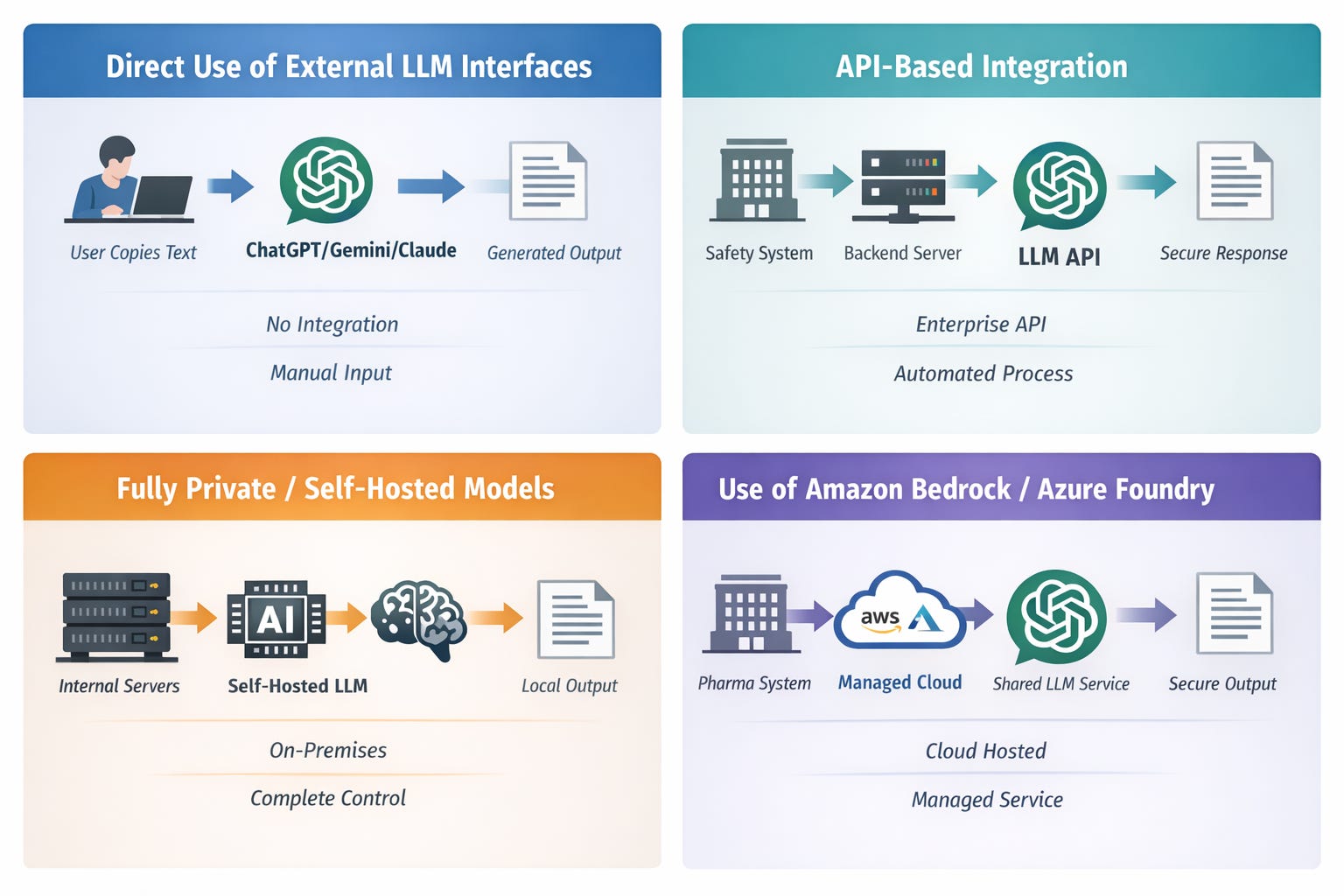
Methodology 1: Direct Use of External LLM Interfaces (Standalone Chat)
This is the most common usage of LLMs. A user manually types or pastes text into an external interface such as ChatGPT, Gemini, or Claude.
For example:
User copies case narrative → pastes into ChatGPT → gets summary
There is no engineering required or integration with enterprise systems. It works immediately and is great for education, brainstorming, training and general search for information. However, if you are uploading or using any sensitive data in chat, it may violate HIPPA, compliance policies, GDPR or other regulations. There is no audit trail. Its manual and not sclabale.
Methodology 2: API-Based Integration (Stateless Processing)
In this method, the companies use LLMs programatically through APIs.
Safety system → backend server → LLM API → response → safety system
Most companies currently operate in this model. They use enterprise offerings from providers such as:
OpenAI
Anthropic (via Amazon Bedrock)
Azure OpenAI / Azure AI Foundry
Enterprise offerings typically ensure below things:
Encryption in transit and at rest
Contractual data protection
No training on customer data (by default)
Access control and logging
Compliance certifications
This model is secure and scalable but requires engineering infrastructure. Importantly, the model still runs inside the provider’s managed cloud infrastructure. It is not self-hosted.
Methodology 3: Fully Private / Self-Hosted Models
In this method, Models run entirely inside the infrastructure or private cloud of the company. There are no external API calls. This method is most secure but expensive. Costs include GPUs, infrastructure and ML engineering teams. Companies like Meta have open-sourced LLM models like (Llamma4). These can be hosted within the company. But the cost of training and maintaining becomes the responsibility of the company. This is the only scenario that qualifies as true self-hosting.
Use of LLMs on Amazon Bedrock or Azure Foundry
Many teams assume that when they use LLMs through Amazon Bedrock or Azure AI Foundry (formerly Azure OpenAI), the model is “inside our environment or VPC.” It is secure, enterprise-grade and feels private. However it is not fully “private” like other cloud components in VPC. So, the natural question is:
If we can have our own VPC and our own servers in the cloud, why can’t we have our own separate LLM instance?
Lets understand it using an example. When you launch a server in AWS or Azure:
You choose the instance.
You control the operating system.
You install your software.
You manage runtime behavior.
Even though the physical hardware is owned by the cloud provider, the virtual machine is dedicated to your account. In that sense, you control the full software stack. This is different from how LLMs are provided on cloud.
When using an LLM through Amazon Bedrock or Azure Foundry, you are still using a “managed” offering. You are not deploying the model yourself. This is what happens:
You send a request to a managed service.
The provider routes that request internally.
The model runs inside their managed inference system.
You receive the output
Below is a summary:

The LLM model is provided as a service, not as deployable software. There is no concept of having “Your own separate GPT-4”. This is because proprietary models like GPT-4 or Claude are not distributed as downloadable model weights. These are not licensed for private deployment and run only inside the provider’s controlled infrastructure. With Bedrock or Azure, you are accessing a shared managed inference layer. Isolation happens at the account and request level and not at the level of “a physically separate model just for you.”
What Companies mean when they say “Our Own ChatGPT”
When the companies say they have “their own ChatGPT deployment,” they typically mean:
They have built an internal application or interface
They have integrated enterprise APIs
They have implemented governance, access control, and logging
They may have connected internal data sources
It does not mean they possess an exclusive, locally hosted copy of GPT-4 or Claude running inside their own data center. It means they are securely using enterprise-managed LLM services under the hood.
Enterprise LLM services such as OpenAI Enterprise, Amazon Bedrock, or Azure AI Foundry provide secure, contractually protected, logically isolated access to powerful models. They do not provide self-hosted deployments of proprietary models.
Understanding this distinction is essential for architectural transparency, regulatory clarity, and informed decision-making.