
Understanding the AI Landscape: A First-Principles Guide for Pharmacovigilance Professionals
From GPT to Gemma, from Hugging Face to Ollama: the AI ecosystem can feel like alphabet soup. This guide builds your intuition from the ground up, with concrete examples from drug safety.

If you work in pharmacovigilance, you've likely heard about "AI" being used for ICSR intake, signal detection, and case narrative generation. But when someone mentions GPT-4, Llama, Hugging Face, and Ollama in the same sentence, it can feel like they're speaking different languages. These terms describe different layers of the same ecosystem. Once you see the layers, the confusion disappears.
The Three-Layer Mental Model
Think of AI the way you think about pharmaceuticals. A drug substance is manufactured by a company, delivered through a dosage form (tablet, injection, patch), and reaches the patient via a distribution channel (hospital pharmacy, retail, mail-order). Confusing the drug with the pharmacy would be absurd. Yet that’s exactly what happens when people equate “ChatGPT” with “GPT-4” or call Ollama “a model.”
The AI ecosystem has three analogous layers:
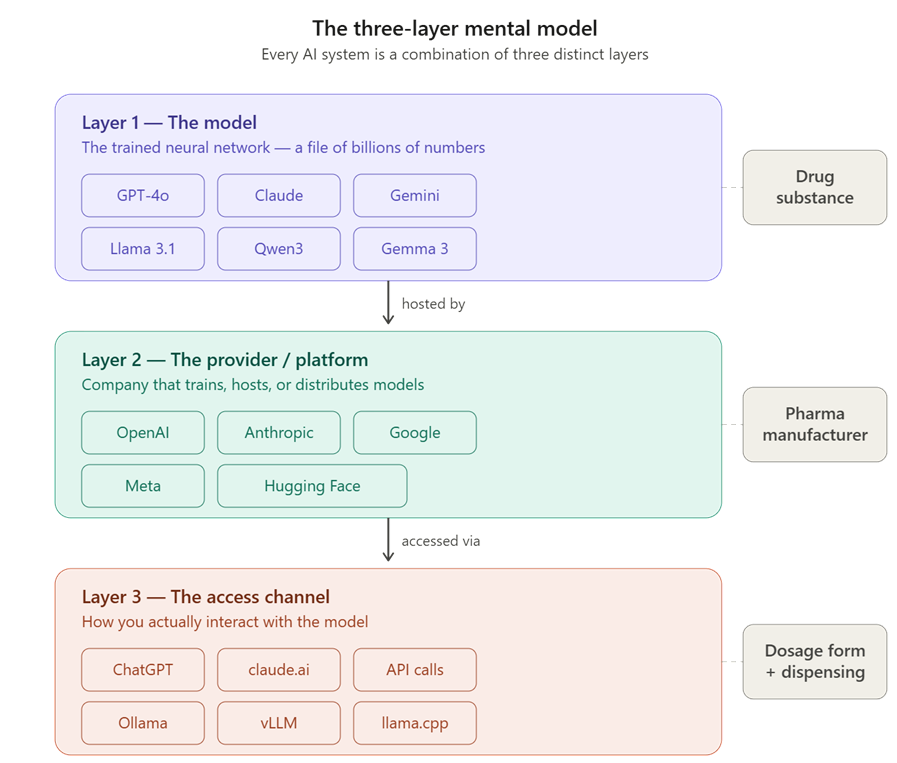
When your organization says "we use AI for ICSR intake," that statement spans all three layers. The model (e.g., a fine-tuned Llama or GPT-4o) extracts structured E2B fields from source documents. The provider (OpenAI, or your own GPU cluster) runs the model. The access channel (an API call from your safety database, or a web UI for case processors) is how your team actually interacts with it.
Open vs. Closed
Every model in the landscape falls on one side of a fundamental divide: closed-weight (proprietary) or open-weight (publicly downloadable). This single distinction determines control, cost structure, privacy posture, and customization options.

Individual Case Safety Reports contain protected health information. When you call a closed API (GPT-4o, Claude), the ICSR data travels to the provider’s servers. Even with BAAs and data processing agreements, some organizations, particularly in the EU and Japan, prefer that patient data never leaves their own infrastructure.
Open-weight models make this possible. You download the model, run it on your own GPUs (on-premise or in your private cloud), and no data ever leaves your controlled environment. This is why many PV AI platforms fine-tune open models like Llama or Qwen for ICSR extraction rather than relying solely on closed APIs.
The Size Spectrum: Small, Medium, and Frontier
Models come in vastly different sizes, measured in parameters (the individual numerical values that encode the model's learned knowledge). More parameters generally means more capability but also more cost, more hardware, and more latency. The right choice depends on the task.

A key insight for PV professionals is that “bigger is not always better”. A medium-sized model that has been fine-tuned on your specific ICSR extraction task(trained to output structured E2B(R3) fields from safety narratives) can outperform a frontier model that has never seen your data format. You are trading generality for domain precision, and for well-defined tasks like populating Patient.Drug.Reaction mappings, domain precision wins.
Hugging Face - The “GitHub of AI”
If you want understand only one infrastructure player beyond the model providers, let it be “Hugging Face”. It is not a model. It is not a company that trains frontier AI. Instead, it plays a role closer to a pharmaceutical distribution and reference library. Its a central hub where the entire AI community shares, discovers, and collaborates on models, datasets, and tools.
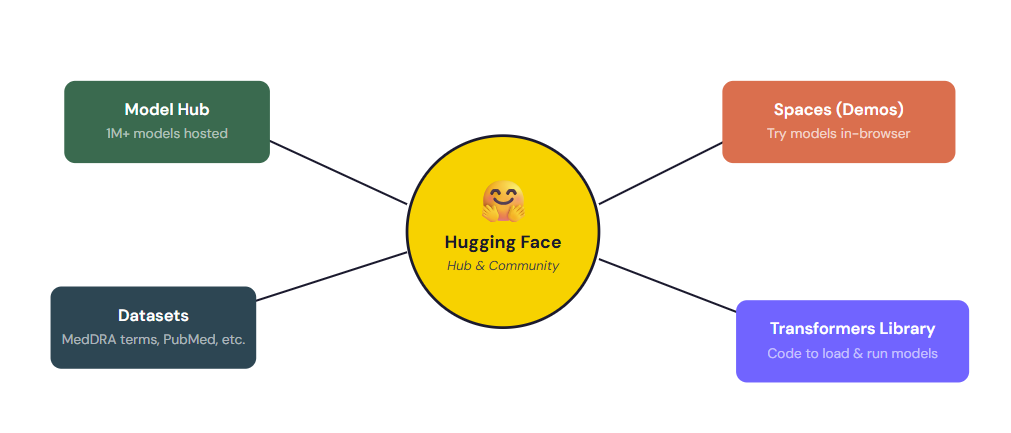
What Hugging Face does ?
Model Hub: The “USP/Pharmacopeia” of AI Models
Over a million models are hosted here. When Meta releases Llama 3.1 or Alibaba releases Qwen3, they publish the weights on Hugging Face. You go there to browse, compare, and download - much like consulting a reference standard catalog.
Datasets: Training Data for Domain-Specific Models
Publicly shared datasets for NER, text classification, and extraction including medical and biomedical datasets. If you’re building a custom model for MedDRA coding or adverse event extraction, the training data likely lives here.
Transformers Library: Universal Adapter
A Python library that lets you load almost any model with a few lines of code. It’s the equivalent of a universal API that speaks every model’s language whether it’s BERT for NER or Qwen3 for full ICSR extraction.
Spaces: Live Demos
Interactive web demos where you can try models in your browser. Before committing GPU budget to a model, you can test whether it handles Japanese PMDA case reports or correctly identifies causality_assessment fields.
Hugging Face is to AI models what GitHub is to source code - a hosting, collaboration, and discovery platform. It doesn't train the flagship models itself (though it has its own smaller models). Its value is in being the neutral commons where the entire open-weight ecosystem converges.
Ollama: Running AI on your own machine
This is where confusion peaks. Ollama is not a model. Ollama is a runtime - a lightweight tool that makes it easy to download and run open-weight models on your own laptop or server. If Hugging Face is the library where you browse models, Ollama is the local workbench where you install and run them.
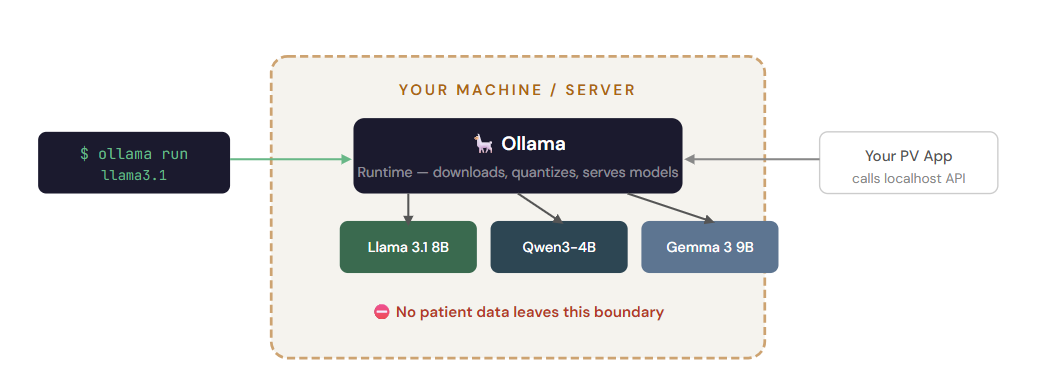
With one terminal command (ollama run llama3.1), Ollama downloads the model, quantizes it to fit your hardware, and spins up a local API server. Your PV application can then call this local endpoint exactly like it would call OpenAI's API, but no data ever leaves your network.
Other runtimes exist for production-scale deployments: vLLM and TGI (Text Generation Inference) are optimized for high-throughput GPU serving, while llama.cpp is optimized for CPU-only machines.
The Full Ecosystem Map
Now let's put it all together. Here's how every piece connects in the context of a pharmacovigilance AI deployment:
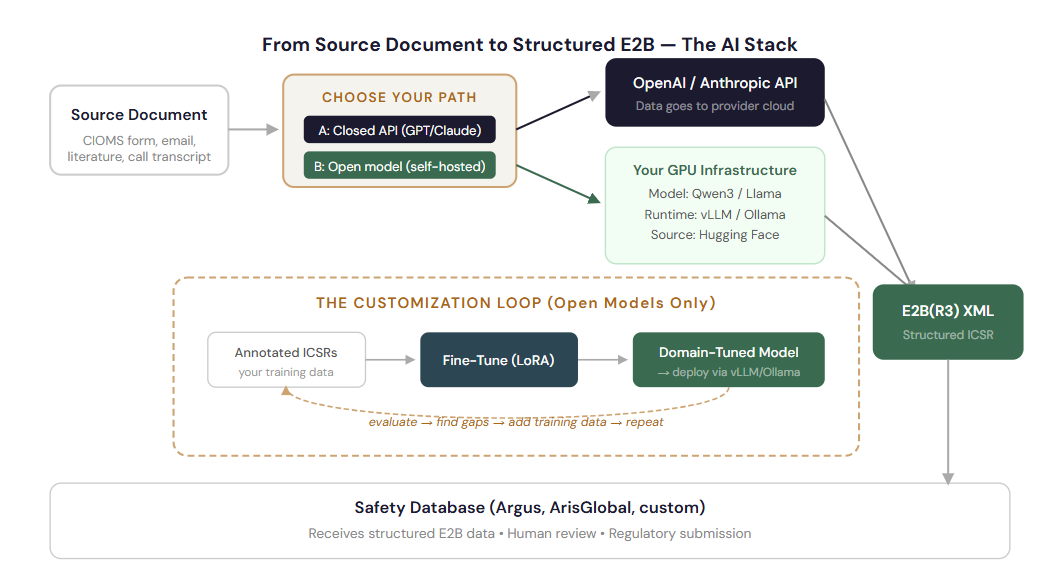
Armed with this mental model, here's how to think about AI decisions in your drug safety operations:
We want to use AI for ICSR intake. Where do we start?
Start with a closed-model API (GPT-4o or Claude) to prototype and validate the extraction quality. Once you've proven value, consider fine-tuning an open model (Llama, Qwen) for production, it gives you data sovereignty, lower per-case cost at scale, and independence from any single vendor.
Our compliance team is worried about patient data going to cloud APIs.
This is exactly what open-weight models solve. Download a model from Hugging Face, run it via vLLM on your private infrastructure, and no patient data ever crosses your network boundary.
How do we know which model to pick?
Go to Hugging Face, filter by size range suitable for your hardware, and test candidates on a sample of your ICSRs. For production extraction, medium models (8B–70B) fine-tuned on your data typically outperform untrained frontier models. Evaluate using field-level F1 scores against your gold-standard annotations.
The Bottomline
The AI landscape is a map with three layers (model, provider, access channel) and one fundamental axis (open vs. closed). Hugging Face is the central library of the open ecosystem. Ollama is the tool that lets you run open models locally. And the right choice for your PV workflow depends not on which model is "best" in a vacuum, but on which combination of capability, privacy, cost, and customizability fits your specific regulatory and operational context.
You are not locked into one option. Many mature PV AI platforms use frontier closed models for complex reasoning tasks (causality assessment, medical review support) while running fine-tuned open models for high-volume structured extraction. The landscape is a toolkit and now you have the map to navigate it.
Remember the Pharma Analogy
Model = Drug substance (the active ingredient). Provider = Manufacturer (who makes and distributes it). Access Channel = Dosage form and dispensing method (how it reaches the patient). Don’t confuse the pharmacy with the medicine.
Written for pharmacovigilance professionals navigating AI adoption. This article provides a conceptual framework. Always evaluate specific models against your organization's regulatory requirements, data governance policies, and validation standards.